Implementation
Data Model
Our data model is a minor variation on the object-oriented model
designed for Web contents. To wrap WISs, our policy is as follows:
- We regard a Web page as a set of complex objects. Thus, web pages
of a common structure are instances of a class. We describe the schema
of this class (= a set of complex objects) by an interface
definition (ID).
- Each ID directly describes a class of a simple structure like a
normalized relation scheme, but it can express complex objects by
using references to other IDs or OR-constructors. Path expressions are
used for specifying data-values at desired positions in the object
structure.
- Further, IDs which directly wrap a WIS are given public methods
which call the inherent service-calls of the UI or DA parts of the
corresponding WIS.
Interface definition:
A general syntax of an ID is as follows:

Figure 1
IDName is the name of ID, and is maintained in a repository
database DatabaseName whose address =
URLofProxyExecutor. An ID has a set of attributes of the form
(A1 � DT1, ... , Ai �
DTi, ... , An � DTn), which describes
data in a page where Ai and DTi are an
attribute and its data type, respectively. Data
types are used for modeling semistructures.
Methods have a form [static] methodName(DT1 �
AR1 , ... , DTn � ARn) where
methodName is the name of the method and DTi is the data
type of the argument ARi. The keyword static says
that the method is a class method in the sense of object-oriented
languages. (The other case implies an instance method.) There are two
types of methods: public and private. The methods
defined in the public part can be used in users' query
command. In contrast, the methods of the private part are
implicitly invoked by the system. The concrete realization of the
methods are described in Perl code in the implement part.
Data type: The following kinds of basic data types are
represented in our data model:
- Domain (denoted by DM). This represents a pool of atomic
data-values(e.g., text, integer) that have exact data-formats and
meanings. Domain is an atomic unit of metadata, used for
resolving semantic conflict between different sources.
- listof IDName. It represents a list of object-ids
which are instances of IDName. This data type is used for
describing a nested structure of Web pages.
- link IDName. It describes an external link to another page
where IDName is the name of the top-level ID that wraps that
page.
Methods: To access a Web page, an ID for the page must have a
public static method. Arguments of such a method depend on
the type of the Web page. In case of a front page (= the 1st page
containing a client application of a WIS) whose url is unique, the
arguments of the method are used to update data in the page. In case
of a result page which is generated by a server, the arguments of the
method are used as data-conditions to access that Web page. In
addition, to interact with the system, a set of methods having
pre-defined names must be given in the private part.
Example:
Page-specific wrapper:
Before describing path expressions, we explain here how the common
data model is used by wrappers.
For each page, there must be a page-specific wrapper to coordinate
between a proxy executor(PE) and the IDs that wrap the page. It works
as follows:
- When the page-specific wrapper receives a query command from
the PE, it invokes associated public methods defined in the IDs to
get a result page.
- Thereafter, it parses the result page, finds data from the
page and creates objects from the data according to the definition
given in the IDs.
- Next, it embeds data-tags into the page, and returns both the
data-objects and the (HTML) page with data-tag to the PE. Using
both of these results, the PE can generate derived links in the
resulting HTML page, which is passed to users' browsers.
By following this procedure, the PE can execute only a subpart of
derived links in the current page, and so it can materialize
navigational integration at a time.
Path Expression:
A data-entry on a Web page can be specified by a path
expression. It has the form
t0->{A1}-> ... ->{Ai}=>IDName ->{Aj} ->... ->{An}
,where t0 is an object variable and {Ai} is an
attribute. An arrow (->) denotes traversing down an edge in a nested
structure of a page. A double arrow (=>) followed by an ID name that
wraps its next result-page denotes traversing an external link between
different pages.
As an example, let D be an object variable of an ID
Department, Then the following path expression
D->{academicPage}=>Academic->{laboratories}->{staffs}->{fullName}
is interpreted to get fullnames of all staffs in all academic
pages in a given instance of Department page.
Query Language
The navigational integration is defined by using a query command. Here
we describe our query language and then how to generate derived links
based on the query command. For simplicity, we assume that only atomic
domains are used in queries.
Our query language is a SQL-like language. It has a syntax as follows:

Figure 2
where:
- OVi is an object variable;
- IDi is a name of an interface definition that wraps
WISi;
- DBi is a repository database name;
- PEi is an url of a proxy executer; and
- Ci is a condition to retrieve a Web page from
WISi.
The Ci is given by a form IDi
->methodNamei(arg(i-1)1,...,arg(i-1)j)
where arguments (arg(i-1)1, ... ,arg(i-1)j) are
constants or path expressions specifying the data of the previous
WIS(WISi-1).
Derived links:
For a given Ci mentioned above, there must be a derived
link from the current page (P(i-1)) to a new page
(Pi) which will be generated from IDi by the
expression
IDi->methodNamei(arg(i-1)1,...,arg(i-1)j). Because
data-values of the arguments
arg(i-1)1,...,arg(i-1)j are found in the current
page P(i-1), we can create a derived link from
P(i-1) to Pi if the source position of the link
is decided. The destination of the link is a new result-page itself.
Currently, the source position of a derived link is set to the
position of arg(i-1)x s.t. arg(i-1)x is the
rightmost leaf at the deepest level in the set of the arguments
arg(i-1)1,...,arg{(i-1)j when the current page
P{(i-1) is regarded as a tree structure. In retrospect, it
would be better to add an location-indicator in a path expression.
The positions can be determined by searching the data-tags
embedded by the page-specific wrapper.
Example
Now, let us show an example of the navigational integration by a
query. Suppose a mobile user wants to find the information of
laboratories and staffs in each laboratory in each floor, by starting
from the client application shown in this
example To do so, he wants to define the navigational integration
over this WIS (denoted by WIS1), a document WWW server of the
department (shown in this example(denoted
by WIS2)), and the Altavista search engine (denoted by WIS3). The
query command is shown as follows:
from B in BldGuideF, D in Department, A in AltaSearch
source BldGuideF of ISBuilding on http://HOST1/cgi-bin/Proxy.pl,
Department of ISInformation on http://HOST2/cgi-bin/Proxy.pl,
AltaSearch of NewAltaVista on http://HOST3/cgi-bin/Proxy.pl
where BldGuideF->getBldForm('','')
and Department->getByKeyWord(B->{submit}=>FloorLabInfo->{lab})
and AltaSearch->getByKey(D->{laboratories}->{staffs}->{fullName})
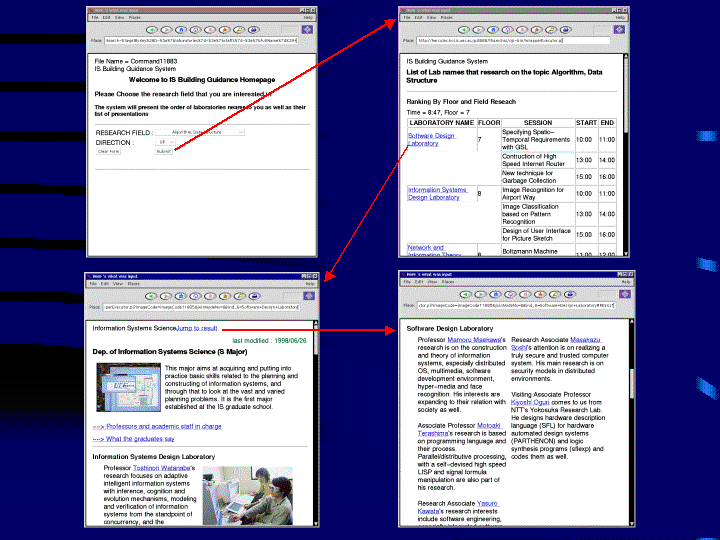
Figure 3
Figure 3 shows how these three WISs work under this query of
navigational integration. Let us explain how the materialization
proceeds under this query:
Firstly, the original front page of WIS1 is created through the
wrapper by running BldGuideF(). When running the second
Where-condition in the above query, a proxy executer must firstly run
the service-invocation corresponding to the submit button. In the
other cases, go proceed to the next page. At the page of the
upperright corner in Fig.3, derived links are now embedded at the
laborotarory names in the result pages of the WIS1. This is to find a
department page containing the required laboratory, bypassing the
front page of WIS2. When the materialization proceeds as the user
issues clicking, derived links (= remaining subqueries) are embedded
at the staff names in the result page of WIS2. These links are to
invoke result pages of the altavista search engine without entering
the staff name into the front page of Altavista. (The result page from
Altavista is not shown in this Figure).
Navigational Integration in Semistructured Documents
The detail of this topic can be seen in this link
Last modified: Mon Apr 24 19:22:32 JST 2000